
高校学科大数据治理模式及学科建设策略研究
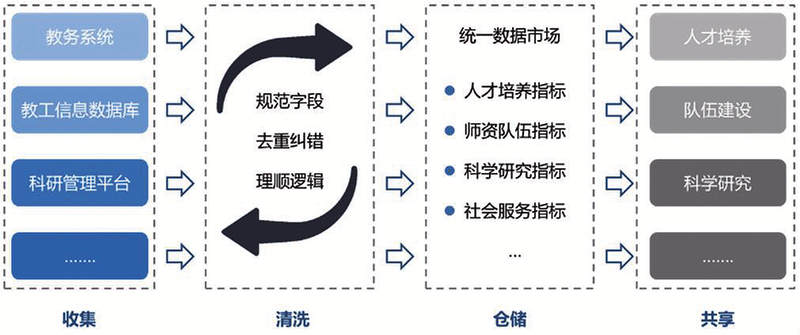 图2:学科大数据治理范式
图2:学科大数据治理范式 后反映的逻辑关系,进而指导学科建设工作实践的过程。
1989年,Gartner Group提出商业智能(BusinessIntelligence,BI)的概念,借助商业智能技术帮助商业机构完成分析、做出决策,被广泛应用于金融、通信、制造与零售等行业领域。由于在商业领域的成功应用,高等教育学界逐步将商业智能的理念、方法及相关技术引入院校管理的实践当中,并衍生出更加适应高等教育需求的学术分析技术(AcademicAnalytics)、学习分析技术(LearningAnalytics),这些技术可以帮助高校管理者对数据进行统计、分析、解释,进而建立预测模型,为教学工作提供帮助。北美高校较早地便将信息化技术应用于院校管理的循证决策之中,[7]伊利诺伊大学建立学校决策支持数据仓库,亚利桑那州立大学为支持科学决策建设了数据仪表盘。[8]在此方面,我国高校虽然起步较晚,但也在快速发展当中,复旦大学实现了在校师生管理信息化的全覆盖,中国人民大学开发出综合数据填报、数据存储、数据管理和数据展示等功能的校园大数据平台,浙江大学初步构建了数据中心、流程平台等平台体系,形成了各业务部门开放协同的数据场景。[9]
学科建设管理工作涉及海量的教学、科研、人才等数据资源,并且大多都是结构化数据或者结构化程度比较高的数据,因此进行学科大数据挖潜具有重要的现实意义,同时也具有很高的可行性与操作性。从学科大数据挖潜的逻辑架构来看,其包含了数据综合治理、多维数据分析与实践策略优化等三个部分,其中数据治理是基础、数据分析是手段、策略优化是目的,三者有机统一且紧密衔接,构成了学科大数据治理挖潜的全周期模型。
学科大数据的综合治理
学科大数据的综合治理是将无序的学科大数据有序化的过程,其治理范式覆盖了数据“收集、清洗、存储、共享”的全生命周期。
(一)规范数据字段定义
数据字段的规范化定义包含界定数据内涵与统一填报格式。界定数据内涵是对数据属性的规范和限定,一条完整的数据由多个不同的数据属性共同构成,通过规范表头字段的描述、形式等,对数据填入进行条件、规则限制,明确数据需求,统一数据统计口径,从源头建立起数据标准。统一填报格式是对数据的表达形式的规定,数据无论以汉字、英文、数字何种形式表达展示,在管理工作者视角下并不会影响信息传递,但对于机器语言而言,非标准的数据统计会降低数据可信度,影响数据在信息化系统中的存储流转,进而出现数据报错、丢失等问题,因而必须限定数据的统一填报格式,使其更便于用机器语言读写翻译。
(二)系统清洗底层数据
系统性清洗学科大数据,重构学科大数据的底层逻辑,是学科大数据综合治理过程中不可或缺的关键步骤。数据清洗是对数据进行处理和加工,使其适合进行分析和建模的一种技术方法,主要包含去除数据重复记录、填补数据缺失值、检测和处理数据异常值、转换数据格式、验证数据准确性和完整性。由于学科大数据体量庞大且类型多样,学科大数据清洗需要借助计算机技术进行批量处理,同时也需要通过人工方式对部分数据归属进行认领,对数据之间的逻辑关系进行确认。数据清洗对学科大数据的完整性、真实性、规范性进行了系统地校准与纠错,同时也对数据字段之间、数据之间的底层逻辑进行了梳理与确认,最大程度地消除了数据错误和噪声,提高了建模和分析的精度。
(三)建立数据仓储市场
建立数据仓储市场的核心是搭建科学合理的数据指标体系。学科大数据可以按照不同维度进行分类,每个维度再按照细分领域划分设置一级指标、二级指标,从而建立起多维分层的指标体系。随着高校学科建设越来越强调内涵式发展,高校在反映数量增长的规模型指标的基础上,更加关注反映质量提升的内涵型指标,例如学科方向、人才团队、学术平台与产出标志性成果的匹配度,高层次人才承担重大重点项目的比例等。这些内涵型指标通常不是可以直接获取的基础指标数据,而是需要通过多个基础指标数据统计计算或者整合分析得到的高阶数据。因而学科建设数据指标体系的构建不仅会随着国家政策导向、高校战略重心调整、学科布局优化以及重点任务改变等因素动态发生变化,数据指标需要像“搭积木”一般根据实际工作需要而构建。
(四)贯通数据流转通路
学科建设管理部门是学科大数据的“使用者”,但不是学科大数据的“制造者”,学科大数据产生于各